《Attention is all you need》

0 Prerequisite knowledge
BLEU分数
BLEU(常读作BLUE)分数全称 Bilingual Evaluation Understudy,原用于评估机器翻译结果,现已广泛用于评估其他语言任务中输出序列的质量。
修正
其中
该公式中有几点值得注意,因为更短的预测序列往往获得更高的
的简短惩罚(BP),用以惩罚比目标序列更短的结果;因为更长的n元词组匹配更难,所以通过:
为其分配更高的权重。
此外,业界习惯将原始BLEU分数 * 100得到惯用的BLEU表示。以下为BLEU分数计算函数:
1 | def bleu(pred_seq, label_seq, k): |
Encoder-Decoder 结构
在通常的seq2seq任务中(如机器翻译等),输出和输出都是未对齐的变长序列,处理此类数据的标准方案是设计一个encoder-decoder结构,该结构包括以下两个主要组成部分:
- Encoder接收变长的序列作为输入,将其编码成固定形状的状态向量,输出状态向量。目的是将变长输入序列映射成固定形状的状态向量。
- Decoder接收Encoder输出的状态向量和已生成序列,预测下一个token。最终目的是将状态向量映射成变长序列。
以下是Encoder-Decoder结构的简单示意图:

Attention Mechanism
注意力机制通过计算查询(query)与键(key)的相似度为各位置分配权重,并对对应的值(value)加权汇聚,从而选择性聚合关键信息、捕获长程依赖并提升表示与并行效率。
其中

具体到序列建模中,每个token通过Attention Mechanism对序列内其他token依赖关系进行建模。
Auto-regressive
自回归是指将序列的当前项建模为在其历史前缀条件下的分布,通过“用过去预测现在”的递推方式进行逐步生成,从而有效捕获时序依赖并保证因果性。
Embedding
将离散的token映射到连续向量,相似词在向量空间更近,便于线性/非线性变换与注意力相似度计算。详见Word Embedding
LayerNorm/BatchNorm
1 Introduction
RNNs对序列沿着时间步逐个计算隐藏状态:
注意力机制进行序列建模,各时间步并行进行,且在对token间依赖关系建模时,token间距离不再成为一种限制。
Transformer结构则完成采用注意力机制进行序列内依赖关系、输入输出序列间依赖关系建模,允许高度的并行化。
2 Background
为解决RNNs的序列性计算问题,过去也提出过一些基于CNN的序列建模方法,能够并行地计算序列内各位置的隐藏状态,但计算数随着两位置间距离增大而增加。在Transformer中,计算数成为常数,不会随着两位置间距离增大而增加。
同时,为解决单头注意力带来的有效分辨率下降,Transformer采用了多头注意力。
Transformer采用self-Attention(或intra-Attention)进行序列内建模
3 Model Architecture
![]()
3.1 Encoder and Decoder Stacks
- Encoder部分由N个相同层堆叠形成,每层又由两个子层组成,首先是self-attention mechanism,其次是位置全连接前馈网络(该FFN在同一层内各位置参数相同,不同层间参数不同)。各子层均采用残差连接。
- Decoder部分也由N个相同层堆叠形成,在Encoder中两个子层的基础上,添加了一个将生成序列self-Attention建模结果与Encoder输出进行cross-attention(交叉注意力)的层。同时Decoder的self-Attention层在通过掩码和目标序列右移一位(teacher forcing)实现预测第i个token时只能看到前i-1个token。
3.2 Attention
关于注意力函数的解释,这里贴一段原文,解释的很清楚明白:
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
3.2.1 Scaled Dot-Product Attention
Transformer采用Scaled Dot-Product Attention(SDPA)计算注意力分数:
SDPA是在Dot-Porduct Attention(DPA)的基础上缩放得到的:
DPA则是在Gaussian Kernel的基础上得到:
下面展示如何从Gaussian Kernel一步步得到SDPA,首先展开上述函数:
上述GK分数经过softmax处理时:
由于
因此GK分数可化简为:
得到Dot-Product Attention分数,假设经过Norm处理的
标准差会随着维度增大,使各项注意力分数的
在实际运用中,我们通常同时按组计算,故将queries、keys、values打包成矩阵Q、K、V进行计算: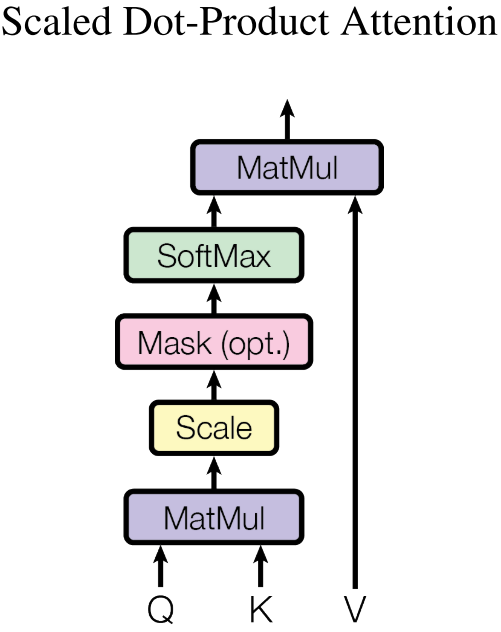
3.2.2 Multi-Head Attention
用
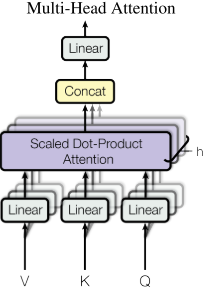
3.3 Position-wise Feed-Forward Networks
该层较简单,公式如下:
3.4 Embedding and Softmax
采用预学习的Embedding矩阵来对Encoder输入和Decoder输出的token进行转换。
3.5 Positional Encoding
由于Transformer没有采用循环或卷积机制,无法利用序列的顺序信息;为利用序列中token的位置信息,Transformer为每个Embedding加入了用于表示绝对位置和相对位置的位置编码:
4 Comparing CNNs, RNNs, and Self-Attention

| Layer Type | Complexity per Layer | Sequential Operations | Maximum Path Length |
|---|---|---|---|
| Self-Attention | |||
| Recurrent | |||
| Convolutional | |||
| Self-Attention(restricted) |
- 标题: 《Attention is all you need》
- 作者: 敖炜
- 创建于 : 2025-10-20 22:39:04
- 更新于 : 2025-10-27 14:59:26
- 链接: https://ao-wei.github.io/2025/10/20/详解Transformer/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。